Dataset Modeling
Prepare datasets for training by analyzing data health, features, and ensuring consistency for benchmarking.
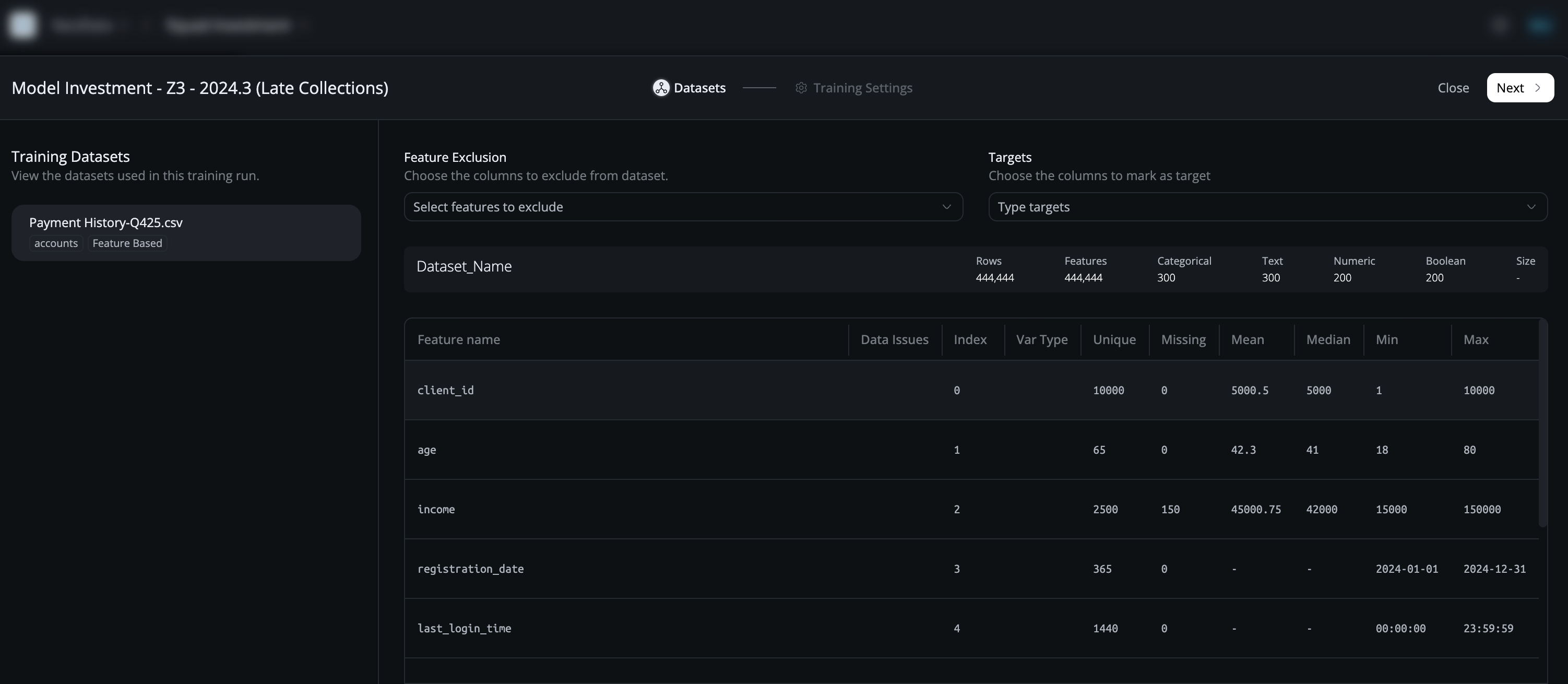
Dataset Health
Dataset health provides insights into data quality and readiness:
Health Metrics:
- Data Quality: Overall data quality score
- Completeness: Percentage of non-null values
- Consistency: Data consistency across features
- Validity: Data validity and format compliance
Health Indicators:
- Healthy: Dataset is in good condition
- Warning: Some issues detected but usable
- Critical: Significant issues that need attention
Health Checks:
- Missing values
- Data type consistency
- Value ranges and distributions
- Outlier detection
- Data format validation
Feature Analysis
Analyze features to understand their characteristics:
Analysis Types:
- Statistical Analysis: Basic statistics for each feature
- Distribution Analysis: Distribution of feature values
- Correlation Analysis: Correlations between features
- Importance Analysis: Feature importance for prediction
Analysis Results:
- Feature Statistics: Mean, median, std dev, etc.
- Value Distributions: Histograms and distributions
- Correlation Matrix: Feature correlations
- Missing Values: Missing value patterns
- Outliers: Outlier detection and analysis
Using Analysis:
- Feature Selection: Use analysis to select features
- Data Quality: Identify data quality issues
- Feature Engineering: Guide feature engineering decisions
- Model Design: Inform model architecture decisions
Benchmark Consistency
Ensure datasets remain consistent for benchmarking:
Consistency Requirements:
- Fixed Schema: Schema should not change
- Fixed Features: Feature set should remain constant
- Fixed Partitioning: Partitioning should be reproducible
- Version Control: Track dataset versions
Consistency Checks:
- Schema validation
- Feature set validation
- Data distribution checks
- Partition validation
Benchmark Datasets:
- Use consistent datasets for fair model comparison
- Maintain dataset versions for reproducibility
- Document dataset characteristics
- Track dataset changes
Preparing for Training
Prepare datasets for training:
Preparation Steps:
- Complete Modeling: Finish feature and target selection
- Configure Partitions: Set up training/validation splits
- Review Health: Check dataset health metrics
- Validate Configuration: Ensure all requirements met
- Process Dataset: Process dataset to make it ready
Preparation Checklist:
- ✅ Dataset structure selected
- ✅ Features selected
- ✅ Targets selected
- ✅ Partitions configured
- ✅ Dataset health acceptable
- ✅ All requirements met
Ready for Training:
- Dataset status is READY
- All required configurations complete
- Data processed and validated
- Available for training jobs
Next Steps
- Learn about Operations to manage datasets
- Check the Usage Guide for best practices