Datasets Overview
Datasets are the foundation of your LDM training. They contain the data that your models learn from, and the NeoSpace platform provides comprehensive tools for creating, managing, and preparing datasets for training.
What are Datasets?
Datasets in NeoSpace are structured collections of data that are used for training LDM models. They can contain structured or unstructured data, and the platform provides tools to analyze, prepare, and optimize datasets for machine learning.
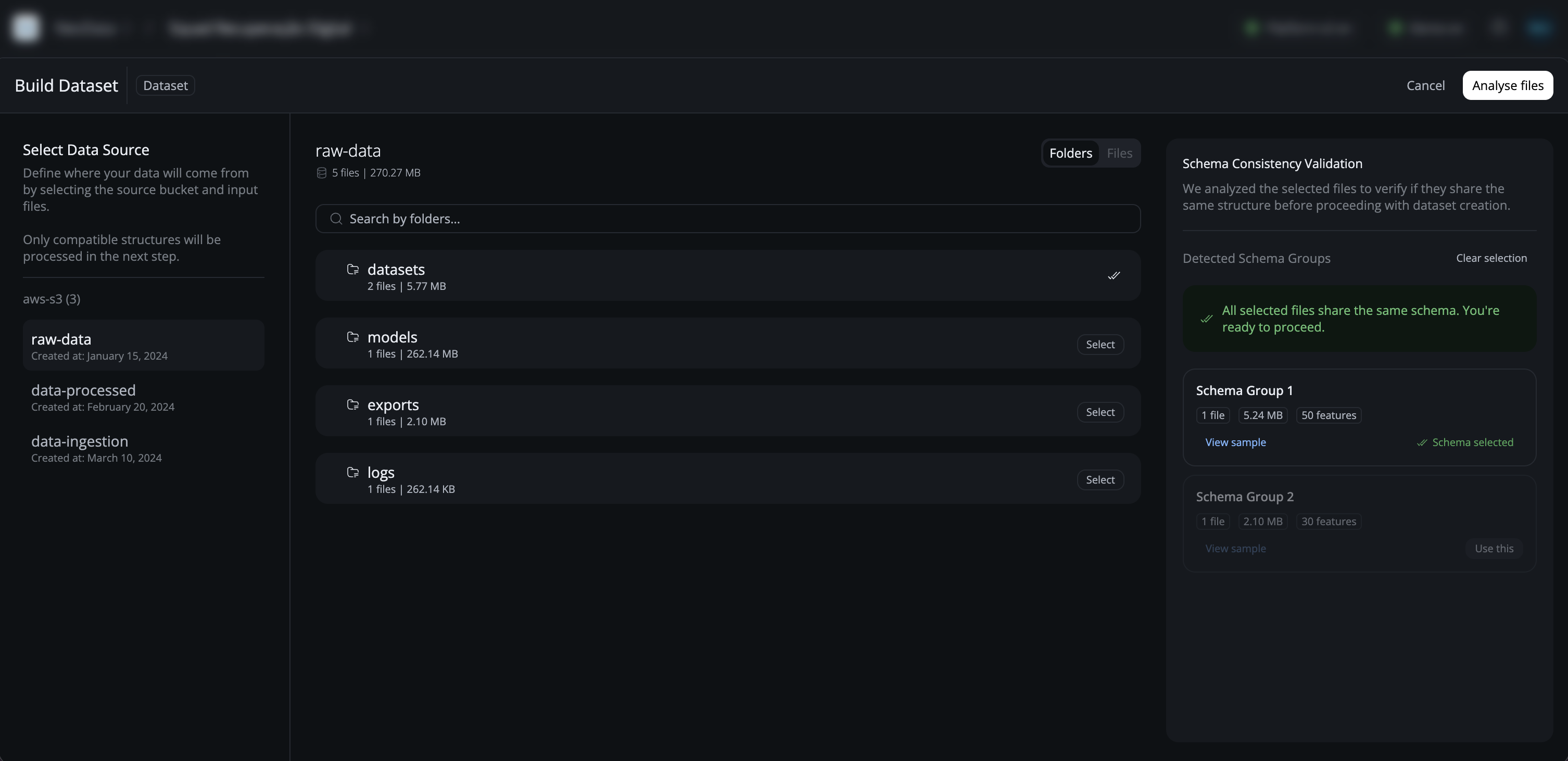
Key Characteristics:
- Data Organization: Organized collections of data from various sources
- Data Analysis: Automatic analysis of data structure and quality
- Feature Engineering: Automatic feature extraction and selection
- Data Preparation: Tools for preparing data for training
- Version Control: Track dataset versions and changes
Why Use Datasets?
Datasets are essential for:
- Model Training: Provide the data that models learn from
- Data Organization: Organize and structure your data for ML workflows
- Data Quality: Ensure data quality through analysis and validation
- Reproducibility: Maintain consistent datasets for reproducible experiments
- Feature Management: Manage features and targets for training
Use Cases
Datasets are used for:
- Training Models: Training LDM models on your data
- Benchmarking: Creating benchmark datasets for model evaluation
- Data Analysis: Analyzing data structure and quality
- Feature Engineering: Extracting and engineering features
- Data Partitioning: Splitting data for training and validation
Next Steps
- Learn about Dataset Types to understand different structures
- Explore Creating Datasets to get started
- Check Modeling to prepare datasets for training
- When Data enhancement is enabled, link ready raw datasets into an enhancement workspace